tf-idf(英语:term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
TF-IDF算法入门知识
TF-IDF是指 "术语频率--逆向文档频率"。这是一种对一组文档中的单词进行量化的技术。我们通常为每个词计算一个分数,以表示它在文档和语料库中的重要性。这种方法是信息检索和文本挖掘中广泛使用的一种技术。
如果我给你一个句子,例如 "这栋楼好高啊"。我们很容易理解这个句子,因为我们知道这些词和句子的语义。但任何程序(例如:Python)如何解释这个句子呢?对于任何编程语言来说,理解以数值形式存在的文本数据是比较容易的。因此,出于这个原因,我们需要对所有的文本进行矢量处理,以便更好地表达它。
通过对文档进行矢量化,我们可以进一步执行多种任务,如寻找相关的文档、排名、聚类等。当你进行谷歌搜索时,就使用了这种确切的技术(现在他们已经更新到了更新的转化器技术)。网页被称为文档,而你用来搜索的文本被称为查询。搜索引擎对所有的文档都有一个固定的表述。当你用一个查询进行搜索时,搜索引擎将找到该查询与所有文件的相关性,按相关性排序,并向你显示前k个文件。所有这些过程都是使用查询和文档的矢量形式完成的。
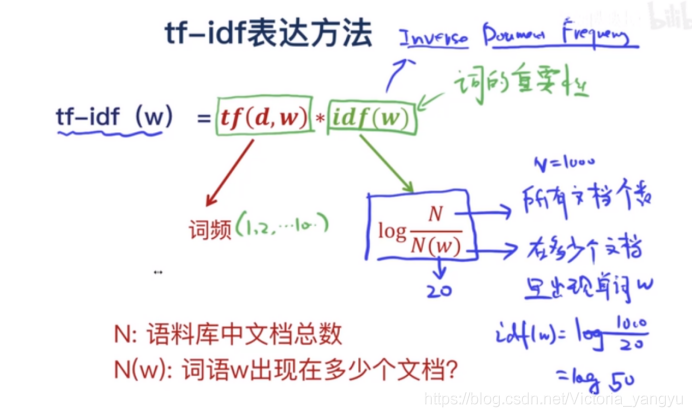
TF-IDF算法公式
TF-IDF = 词频 (TF) * 逆文档频率 (IDF)
术语解释
- t — 术语(词)
- d — 文档(单词集)
- N - 语料库的数量
- corpus — 总文档集
词频
这测量了一个词在文档中的频率。这在很大程度上取决于文档的长度和单词的通用性,例如,一个非常常见的单词如“was” 可以在文档中出现多次。但是如果我们分别取两个分别有 100 个单词和 10,000 个单词的文档,在 10,000 个单词的文档中,很可能常见的单词“was”出现得更多。但是我们不能说较长的文档比较短的文档更重要。正是出于这个原因,我们对频率值进行归一化,我们将频率除以文档中的总字数。
回想一下,我们最终需要对文档进行矢量化。当我们计划对文档进行矢量化时,我们不能只考虑该特定文档中存在的单词。如果我们这样做,那么两个文档的向量长度将不同,计算相似度将不可行。所以,我们要做的是对vocab上的文档进行矢量化。Vocab 是语料库中所有可能世界的列表。
我们需要所有词汇的字数和文档的长度来计算 TF。如果特定文档中不存在该术语,则该特定文档的特定 TF 值将为 0。在极端情况下,如果文档中的所有单词都相同,则 TF 将为 1。归一化 TF 值的最终值将在 [0 到 1] 的范围内。0, 1 包括在内。
TF 对于每个文档和单词都是独立的,因此我们可以将 TF 公式化如下:
tf(t,d) = d 中 t 的数量 / d 中的单词数
如果我们已经计算了 TF 值并且如果这产生了文档的矢量化形式,为什么不只使用 TF 来查找文档之间的相关性呢?为什么我们需要 IDF?
让我解释一下,最常见的词,如“是”、“是”将具有非常高的值,从而赋予这些词非常高的重要性。但是使用这些词来计算相关性会产生不好的结果。这些常见的词被称为停用词。尽管我们将在预处理步骤的后面删除停用词,但在整个文档中找到该词的存在并以某种方式降低其权重更为理想。
文件频率
这 衡量了整个语料库中文档的重要性。这与 TF 非常相似,但唯一的区别是 TF 是文档 d 中术语 t 的频率计数器,而 DF 是文档集 N 中术语 t的出现次数。换句话说,DF 是存在该词的文档。如果该术语在文档中至少出现一次,我们就考虑一次出现,我们不需要知道该术语出现的次数。
df(t) = 在 N 个文档中出现 t
为了将其保持在一个范围内,我们通过除以文档总数进行标准化。我们的主要目标是知道一个术语的信息量,而 DF 是它的精确逆。这就是为什么我们反转 DF
逆向文档频率
IDF 是文档频率的倒数,它衡量术语 t 的信息量。当我们计算 IDF 时,对于最常出现的词,例如停用词,它会非常低(因为它们几乎出现在所有文档中,而 N/df 会给该词一个非常低的值)。这最终给出了我们想要的,相对权重。
idf(t) = N/df
现在 IDF 几乎没有其他问题,当我们有一个很大的语料库大小时,比如 N=10000,IDF 值会爆炸。因此,为了抑制这种影响,我们采用 IDF 的对数。
在查询时,当单词不存在于 is not in the vocab 时,它将被简单地忽略。但是在少数情况下,我们使用固定的词汇,并且文档中可能缺少词汇中的几个词,在这种情况下,df 将为 0。由于我们不能除以 0,我们通过在分母上加 1 来平滑该值.
idf(t) = log(N/(df + 1))
最后,通过取 TF 和 IDF 的乘积值,我们得到 TF-IDF 分数。
TF-IDF算法举例
本示例来自CSDN博主「lawenliu」,原文:https://blog.csdn.net/lwc5411117/article/details/84135182
让我看下用python如何计算文档的TF-IDF的例子。下面实现了对于raw text文档计算TF-IDF之后,然后可以实现根据关键字搜索top n相关文档的例子,简单模拟搜索引擎的小功能。(当然搜索引擎的架构还是比较复杂的,找个时间可以聊一聊。现在很多聊天工具基本也都是:语音识别+语音分析+搜索引擎,可见搜索是未来的一个趋势,也是简化我们生活的方式。5年前做搜索引擎的时候,大家就在讨论未来的搜索引擎是什么,大家更多考虑基于语音的搜索,Google、Apple和微软领先推出了语音助手搜索工具:Google Assistant、Siri、Cortana,紧接着国内就疯狂的刷语音助手。现在搜索引擎已经从传统的网页搜索引擎转换为了语音助手。)
例子比较简单,大家看代码注释就行了,不过多的讲解了。用高级语言写程序的原则:能用但中函数名和变量名表达清楚的,就少加注释。
#!/usr/bin/python
# encoding: UTF-8
import re
import os
import sys
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
class DocumentMg:
def __init__(self, orig_file_dir, seg_file_dir, tfidf_file_dir):
print('Document manager is initializing...')
self.orig_file_dir = orig_file_dir
self.seg_file_dir = seg_file_dir
self.tfidf_file_dir = tfidf_file_dir
if not os.path.exists(self.seg_file_dir):
os.mkdir(self.seg_file_dir)
if not os.path.exists(tfidf_file_dir):
os.mkdir(tfidf_file_dir)
# get all file in the directory
def get_file_list(self, dir):
file_list = []
files = os.listdir(dir)
for f in files:
if f[0] == '.' or f[0] == '..':
pass
else:
file_list.append(f)
return file_list
# keep English, digital and ' '
def clean_eng_data(self, data):
comp = re.compile("[^ ^a-z^A-Z^0-9]")
return comp.sub('', data)
# keep Chinese, English and digital and '.'
def clean_chinese_data(self, data):
comp = re.compile("[^\u4e00-\u9fa5^.^a-z^A-Z^0-9]")
return comp.sub('', data)
# split file content as word list
def split_to_word(self, file_name):
fi = open(self.orig_file_dir + '/' + file_name, 'r+', encoding='UTF-8')
data = fi.read()
fi.close()
clean_data = self.clean_eng_data(data)
seg_list = clean_data.split(' ')
result = []
for seg in seg_list:
if (seg != ' ' and seg != '\n' and seg != '\r\n'):
result.append(seg)
fo = open(self.seg_file_dir + '/' + file_name, 'w+')
fo.write(' '.join(result))
fo.close()
# compute tfidf and save to file
def compute_tfidf(self):
all_file_list = self.get_file_list(self.orig_file_dir)
for f in all_file_list:
self.split_to_word(f)
corpus = []
for fname in all_file_list:
file_path = self.seg_file_dir + '/' + fname
f = open(file_path, 'r+')
content = f.read()
f.close()
corpus.append(content)
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
for i in range(len(weight)):
tfidf_file = self.tfidf_file_dir + '/' + all_file_list[i]
print (u'-------------Writing tf-idf result in the file ', tfidf_file, '----------------')
f = open(tfidf_file, 'w+')
for j in range(len(word)):
f.write(word[j] + " " + str(weight[i][j]) + '\n')
f.close()
# init search engine
def init_search_engine(self):
self.global_weight = {}
all_file_list = self.get_file_list(self.tfidf_file_dir)
# if file not exist, we need regenerate. It will work on first time
if len(all_file_list) == 0:
doc_mg.compute_tfidf()
all_file_list = self.get_file_list(self.tfidf_file_dir)
for fname in all_file_list:
file_path = self.tfidf_file_dir + '/' + fname
f = open(file_path, 'r+')
line = f.readline()
file_weight = {}
while line:
parts = line.split(' ')
if len(parts) != 2:
continue
file_weight[parts[0]] = float(parts[1])
line = f.readline()
self.global_weight[fname] = file_weight
f.close()
# preprocess query
def preprocess_query(self, query):
clean_data = self.clean_eng_data(query)
seg_list = clean_data.split(' ')
result = []
for seg in seg_list:
if (seg != ' ' and seg != '\n' and seg != '\r\n'):
result.append(seg)
return result
# search releated top n file, you can try to use min-heap to implement it.
# but here we will use limited insertion
def search_related_files(self, query, top_num):
keywords = self.preprocess_query(query)
top_docs = []
for fname in self.global_weight:
# calculate document weight
fweight = 0
for word in keywords:
if word in self.global_weight[fname].keys():
fweight += self.global_weight[fname][word]
# instert document weight
idx = 0
for idx in range(len(top_docs)):
if fweight < top_docs[idx]['fweight']:
break
top_docs.insert(idx, {'fname': fname, 'fweight': fweight})
# remove exceed document weight
if len(top_docs) > top_num:
top_docs.remove(top_docs[0])
return top_docs
if __name__ == '__main__':
if len(sys.argv) < 2:
print('Usage: python tf-idf.py <orign file path>')
sys.exit()
orig_file_dir = sys.argv[1] # the folder to store your plain text files
seg_file_dir = './tfidf_data/seg_file' # the folder to store split text files
tfidf_file_dir = './tfidf_data/tfidf_file' # the folder to store tfidf result
# initialize document manager
doc_mg = DocumentMg(orig_file_dir, seg_file_dir, tfidf_file_dir)
# initialzie search engine
doc_mg.init_search_engine()
query = 'understand cable bar'
# search query and get top documents with weight
doc_list = doc_mg.search_related_files(query, 2)
print('query is: ', query)
print('result is: ')
print(doc_list)



